Steam store
Archives .pac - Aluigi's script for Neptunia Re;Birth1.
Archives .cl3 - provided file.
Archives .arc - provided file.
No re-import.
UPD 2018-02-01: after a very long while I've finally made it for .arc files which are used in Megadimension Neptunia VII DLCs (.pac -> .arc -> .cl3)
[PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
-
TheUkrainianBard
- Posts: 121
- Joined: Sun May 01, 2016 10:06 pm
[PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
Last edited by TheUkrainianBard on Wed Jan 31, 2018 11:33 pm, edited 3 times in total.
-
Panzerdroid
- Posts: 66
- Joined: Sun Aug 30, 2015 12:51 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
Reimport is impossible. Only neptunia decompression is available in QuickBMS.
-
Savage
- Posts: 176
- Joined: Thu Oct 02, 2014 4:58 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
Panzerdroid wrote:Reimport is impossible. Only neptunia decompression is available in QuickBMS.
Exactly i confirm this
Error: unsupported compression 498 in reimport mode
Last script line before the error or that produced the error:
26 clog NAME OFFSET ZSIZE SIZE
-
Savage
- Posts: 176
- Joined: Thu Oct 02, 2014 4:58 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
Here is some tools, in japanese i no have no idea how it works
https://steamcommunity.com/sharedfiles/ ... =409454600
https://mega.nz/#!ckAUlLQb!jZSDeRiE2KeP ... MUgORySzn8
https://steamcommunity.com/sharedfiles/ ... =409454600
https://mega.nz/#!ckAUlLQb!jZSDeRiE2KeP ... MUgORySzn8
-
TheUkrainianBard
- Posts: 121
- Joined: Sun May 01, 2016 10:06 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
Panzerdroid, Savage
Thanks, I forgot how many factors there were in re-import.
There are tools named "kitserver" and "neptools", which re-route game's file requests (I dunno how to word it), but their confirmed compability is with Re;Birth games.
Thanks, I forgot how many factors there were in re-import.
There are tools named "kitserver" and "neptools", which re-route game's file requests (I dunno how to word it), but their confirmed compability is with Re;Birth games.
-
Savage
- Posts: 176
- Joined: Thu Oct 02, 2014 4:58 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
Modding tool for the Hyperdimension Neptunia series games; enable packing/unpacking of resources from the games' custom archive format
https://github.com/agentOfChaos/oversized_syringe
Here is the code compression (i think)
https://github.com/agentOfChaos/oversiz ... ression.py
I don't know if can be implemented in the next version of quickbms for reimport
https://github.com/agentOfChaos/oversized_syringe
Here is the code compression (i think)
https://github.com/agentOfChaos/oversiz ... ression.py
Code: Select all
import struct
import os
from ovsylib.compresion_algos import yggdrasil
from ovsylib.aggressive_threading import Broker
from threading import Thread
intsize = 4
def checksize(binfile):
old_file_position = binfile.tell()
binfile.seek(0, os.SEEK_END)
size = binfile.tell()
binfile.seek(old_file_position, os.SEEK_SET)
return size
class BadMagicNum(Exception):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
class algo1:
def __init__(self, id, size):
self.uncomp_size = 0
self.comp_size = 0
self.rootaddress = 0
self.header_write_back_offset = 0
self.id = id
self.size = size
self.bitstream = None
def loadSubHeaderFromFile(self, binfile):
self.uncomp_size = struct.unpack("I", binfile.read(intsize))[0]
self.comp_size = struct.unpack("I", binfile.read(intsize))[0]
self.rootaddress = struct.unpack("I", binfile.read(intsize))[0]
def decompress(self, binfile, metadata_offset, savefile, debuggy=False):
binfile.seek(metadata_offset + self.rootaddress, 0)
yggdrasil.uncompress(binfile, savefile, self.comp_size, self.uncomp_size, debuggy=debuggy)
def writeSubHeader(self, savefile, dry_run=False):
self.header_write_back_offset = savefile.tell()
if not dry_run:
savefile.write(struct.pack("I", self.uncomp_size))
savefile.write(struct.pack("I", self.comp_size))
savefile.write(struct.pack("I", self.rootaddress))
def writeToFile(self, savefile, metadata_offset, dry_run=False):
""" actually writes out the compressed data. Can be run only after compress """
assert self.bitstream is not None
self.rootaddress = savefile.tell() - metadata_offset
savefile.write(self.bitstream.tobytes())
afterwrite_offset = savefile.tell()
savefile.seek(self.header_write_back_offset, 0)
self.writeSubHeader(savefile, dry_run=dry_run)
savefile.seek(afterwrite_offset, 0)
self.bitstream = None # free memory
def compress(self, sourcefile, debuggy=False):
""" this method can be parallelized, given different file handles to the various threads
:return: self """
total_filesize = checksize(sourcefile)
self.uncomp_size = self.size
if (self.size * (self.id + 1)) > total_filesize:
self.uncomp_size = total_filesize - (self.size * self.id)
self.bitstream = yggdrasil.compress(sourcefile,
self.size * self.id,
(self.size * self.id) + self.uncomp_size,
debuggy=debuggy)
self.comp_size = self.bitstream.buffer_info()[1]
return self
def printInfo(self):
print("partial comp size: %d ; partial uncomp size: %d ; relative root address: %x"
% (self.comp_size, self.uncomp_size, self.rootaddress))
class after_comp_callback:
""" used as a callback to fill the 'compressed size' value in places where it was
needed, but we didn't know it yet """
def __init__(self, address, binfile):
self.address = address
self.binfile = binfile
def compressed(self, length, dry_run=False):
savedpos = self.binfile.tell()
self.binfile.seek(self.address, 0)
if not dry_run:
self.binfile.write(struct.pack("I", length))
self.binfile.seek(savedpos, 0)
# need to be standalone, for multiprocess to pickle it
def spawn(chunk, sourcefile_name, debuggy):
with open(sourcefile_name, "rb") as sourcefile:
return chunk.compress(sourcefile, debuggy=debuggy)
class chuunicomp:
default_chunksize = 0x20000
def __init__(self):
self.magicseq = 0
self.chunk_num = 0
self.chunksize = 0
self.header_size = 0
self.chunks = []
self.aftercompress_callback_obj = None
def fromBinfile(self, binfile):
self.magicseq = struct.unpack("I", binfile.read(intsize))[0]
self.chunk_num = struct.unpack("I", binfile.read(intsize))[0]
self.chunksize = struct.unpack("I", binfile.read(intsize))[0]
self.header_size = struct.unpack("I", binfile.read(intsize))[0]
self.chunks = self.prepareChunks(binfile)
if self.magicseq != 0x1234:
raise BadMagicNum(self.magicseq)
def fromFutureImport(self, chunksnum):
self.magicseq = 0x1234
self.chunk_num = chunksnum
self.chunksize = self.default_chunksize
self.chunks = self.prepareChunks(None)
self.header_size = (4 + (3 * chunksnum)) * 4
def prepareChunks(self, binfile=None):
body = []
for i in range(self.chunk_num):
piece = algo1(i, self.chunksize)
if binfile is not None:
piece.loadSubHeaderFromFile(binfile)
body.append(piece)
return body
def decompress(self, binfile, savefile, debuggy=False):
""" we don't read the header at decompression time, since we have already acquired the data
via fromBinfile(). Hence we simply skip the header """
binfile.seek(self.header_size, 1)
metadata_offset = binfile.tell()
for chunk in self.chunks:
chunk.decompress(binfile, metadata_offset, savefile, debuggy=debuggy)
def writeHeader(self, savefile, dry_run=False):
if not dry_run:
savefile.write(struct.pack("I", self.magicseq))
savefile.write(struct.pack("I", self.chunk_num))
savefile.write(struct.pack("I", self.chunksize))
savefile.write(struct.pack("I", self.header_size))
def compress(self, sourcefile_name, savefile, dry_run=False, debuggy=False):
""" run the compression algorithm for each chunk, in parallel. Note that the
caller has the duty to set the file seek in the right position before calling this. """
totalcomp = 0
threads = Broker(len(self.chunks), debugmode=debuggy, greed=1)
def spawnAll(chunklist):
for chunk in chunklist:
threads.appendNfire(spawn, (chunk, sourcefile_name, debuggy))
self.writeHeader(savefile, dry_run=dry_run)
for chunk in self.chunks:
chunk.writeSubHeader(savefile, dry_run=dry_run)
metadata_offset = savefile.tell()
# this thread will feed the broker with tasks
Thread(target=spawnAll, args=(self.chunks,)).start()
# gather all the results, write them in sequence
collected = 0
while collected < len(self.chunks):
for partial in threads.collect():
totalcomp += partial.bitstream.buffer_info()[1]
partial.writeToFile(savefile, metadata_offset, dry_run=dry_run)
collected += 1
threads.stop()
if self.aftercompress_callback_obj is not None:
self.aftercompress_callback_obj.compressed(totalcomp + self.header_size, dry_run=dry_run)
return totalcomp + 4
def printInfo(self):
print(" Compression chunks: %d , header size: %04x" % (self.chunk_num, self.header_size))
for chunk in self.chunks:
print(" chunk #%03d: " % (self.chunks.index(chunk),), end="")
chunk.printInfo()I don't know if can be implemented in the next version of quickbms for reimport
-
Curxe
- Posts: 2
- Joined: Sun Jul 31, 2016 5:31 am
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
Savage wrote:Modding tool for the Hyperdimension Neptunia series games; enable packing/unpacking of resources from the games' custom archive format
https://github.com/agentOfChaos/oversized_syringe
Here is the code compression (i think)
https://github.com/agentOfChaos/oversiz ... ression.pyCode: Select all
import struct
import os
from ovsylib.compresion_algos import yggdrasil
from ovsylib.aggressive_threading import Broker
from threading import Thread
intsize = 4
def checksize(binfile):
old_file_position = binfile.tell()
binfile.seek(0, os.SEEK_END)
size = binfile.tell()
binfile.seek(old_file_position, os.SEEK_SET)
return size
class BadMagicNum(Exception):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
class algo1:
def __init__(self, id, size):
self.uncomp_size = 0
self.comp_size = 0
self.rootaddress = 0
self.header_write_back_offset = 0
self.id = id
self.size = size
self.bitstream = None
def loadSubHeaderFromFile(self, binfile):
self.uncomp_size = struct.unpack("I", binfile.read(intsize))[0]
self.comp_size = struct.unpack("I", binfile.read(intsize))[0]
self.rootaddress = struct.unpack("I", binfile.read(intsize))[0]
def decompress(self, binfile, metadata_offset, savefile, debuggy=False):
binfile.seek(metadata_offset + self.rootaddress, 0)
yggdrasil.uncompress(binfile, savefile, self.comp_size, self.uncomp_size, debuggy=debuggy)
def writeSubHeader(self, savefile, dry_run=False):
self.header_write_back_offset = savefile.tell()
if not dry_run:
savefile.write(struct.pack("I", self.uncomp_size))
savefile.write(struct.pack("I", self.comp_size))
savefile.write(struct.pack("I", self.rootaddress))
def writeToFile(self, savefile, metadata_offset, dry_run=False):
""" actually writes out the compressed data. Can be run only after compress """
assert self.bitstream is not None
self.rootaddress = savefile.tell() - metadata_offset
savefile.write(self.bitstream.tobytes())
afterwrite_offset = savefile.tell()
savefile.seek(self.header_write_back_offset, 0)
self.writeSubHeader(savefile, dry_run=dry_run)
savefile.seek(afterwrite_offset, 0)
self.bitstream = None # free memory
def compress(self, sourcefile, debuggy=False):
""" this method can be parallelized, given different file handles to the various threads
:return: self """
total_filesize = checksize(sourcefile)
self.uncomp_size = self.size
if (self.size * (self.id + 1)) > total_filesize:
self.uncomp_size = total_filesize - (self.size * self.id)
self.bitstream = yggdrasil.compress(sourcefile,
self.size * self.id,
(self.size * self.id) + self.uncomp_size,
debuggy=debuggy)
self.comp_size = self.bitstream.buffer_info()[1]
return self
def printInfo(self):
print("partial comp size: %d ; partial uncomp size: %d ; relative root address: %x"
% (self.comp_size, self.uncomp_size, self.rootaddress))
class after_comp_callback:
""" used as a callback to fill the 'compressed size' value in places where it was
needed, but we didn't know it yet """
def __init__(self, address, binfile):
self.address = address
self.binfile = binfile
def compressed(self, length, dry_run=False):
savedpos = self.binfile.tell()
self.binfile.seek(self.address, 0)
if not dry_run:
self.binfile.write(struct.pack("I", length))
self.binfile.seek(savedpos, 0)
# need to be standalone, for multiprocess to pickle it
def spawn(chunk, sourcefile_name, debuggy):
with open(sourcefile_name, "rb") as sourcefile:
return chunk.compress(sourcefile, debuggy=debuggy)
class chuunicomp:
default_chunksize = 0x20000
def __init__(self):
self.magicseq = 0
self.chunk_num = 0
self.chunksize = 0
self.header_size = 0
self.chunks = []
self.aftercompress_callback_obj = None
def fromBinfile(self, binfile):
self.magicseq = struct.unpack("I", binfile.read(intsize))[0]
self.chunk_num = struct.unpack("I", binfile.read(intsize))[0]
self.chunksize = struct.unpack("I", binfile.read(intsize))[0]
self.header_size = struct.unpack("I", binfile.read(intsize))[0]
self.chunks = self.prepareChunks(binfile)
if self.magicseq != 0x1234:
raise BadMagicNum(self.magicseq)
def fromFutureImport(self, chunksnum):
self.magicseq = 0x1234
self.chunk_num = chunksnum
self.chunksize = self.default_chunksize
self.chunks = self.prepareChunks(None)
self.header_size = (4 + (3 * chunksnum)) * 4
def prepareChunks(self, binfile=None):
body = []
for i in range(self.chunk_num):
piece = algo1(i, self.chunksize)
if binfile is not None:
piece.loadSubHeaderFromFile(binfile)
body.append(piece)
return body
def decompress(self, binfile, savefile, debuggy=False):
""" we don't read the header at decompression time, since we have already acquired the data
via fromBinfile(). Hence we simply skip the header """
binfile.seek(self.header_size, 1)
metadata_offset = binfile.tell()
for chunk in self.chunks:
chunk.decompress(binfile, metadata_offset, savefile, debuggy=debuggy)
def writeHeader(self, savefile, dry_run=False):
if not dry_run:
savefile.write(struct.pack("I", self.magicseq))
savefile.write(struct.pack("I", self.chunk_num))
savefile.write(struct.pack("I", self.chunksize))
savefile.write(struct.pack("I", self.header_size))
def compress(self, sourcefile_name, savefile, dry_run=False, debuggy=False):
""" run the compression algorithm for each chunk, in parallel. Note that the
caller has the duty to set the file seek in the right position before calling this. """
totalcomp = 0
threads = Broker(len(self.chunks), debugmode=debuggy, greed=1)
def spawnAll(chunklist):
for chunk in chunklist:
threads.appendNfire(spawn, (chunk, sourcefile_name, debuggy))
self.writeHeader(savefile, dry_run=dry_run)
for chunk in self.chunks:
chunk.writeSubHeader(savefile, dry_run=dry_run)
metadata_offset = savefile.tell()
# this thread will feed the broker with tasks
Thread(target=spawnAll, args=(self.chunks,)).start()
# gather all the results, write them in sequence
collected = 0
while collected < len(self.chunks):
for partial in threads.collect():
totalcomp += partial.bitstream.buffer_info()[1]
partial.writeToFile(savefile, metadata_offset, dry_run=dry_run)
collected += 1
threads.stop()
if self.aftercompress_callback_obj is not None:
self.aftercompress_callback_obj.compressed(totalcomp + self.header_size, dry_run=dry_run)
return totalcomp + 4
def printInfo(self):
print(" Compression chunks: %d , header size: %04x" % (self.chunk_num, self.header_size))
for chunk in self.chunks:
print(" chunk #%03d: " % (self.chunks.index(chunk),), end="")
chunk.printInfo()
I don't know if can be implemented in the next version of quickbms for reimport
Ok, how do I use the code? This is my first time breaking down game file.
-
TheUkrainianBard
- Posts: 121
- Joined: Sun May 01, 2016 10:06 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
Heck if I know, I have no experience with Python whatsoever.
-
TheUkrainianBard
- Posts: 121
- Joined: Sun May 01, 2016 10:06 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
After a very long while I've finally made it for .arc files which are used in Megadimension Neptunia VII DLCs
-
Razzee
- Posts: 2
- Joined: Fri Mar 29, 2019 7:34 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
Hello. Is this add-on compatible with Neptunia VII only? I'm trying to extract .cl3 files from Trinity Universe folder, a precursor of the Neptunia franchise.

Found a add-on similar to yours, but it gives the same error. Tried NepTools, and it didn't work either. I'm out of ideas.
The file:
https://mega.nz/#!Q893HaAC!tcCRuwNsHAVV ... nHcZ45nDHw
Found a add-on similar to yours, but it gives the same error. Tried NepTools, and it didn't work either. I'm out of ideas.
The file:
https://mega.nz/#!Q893HaAC!tcCRuwNsHAVV ... nHcZ45nDHw
-
TheUkrainianBard
- Posts: 121
- Joined: Sun May 01, 2016 10:06 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
PS3 is a Big Endian platform, try this.
-
Razzee
- Posts: 2
- Joined: Fri Mar 29, 2019 7:34 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
Yes, it worked. Thanks for the fast response.
Yesterday I edited a main.dat (which I didn't have to extract from a .cl3) and once I added it to the game, every text inside that file disappeared.
[spoiler]
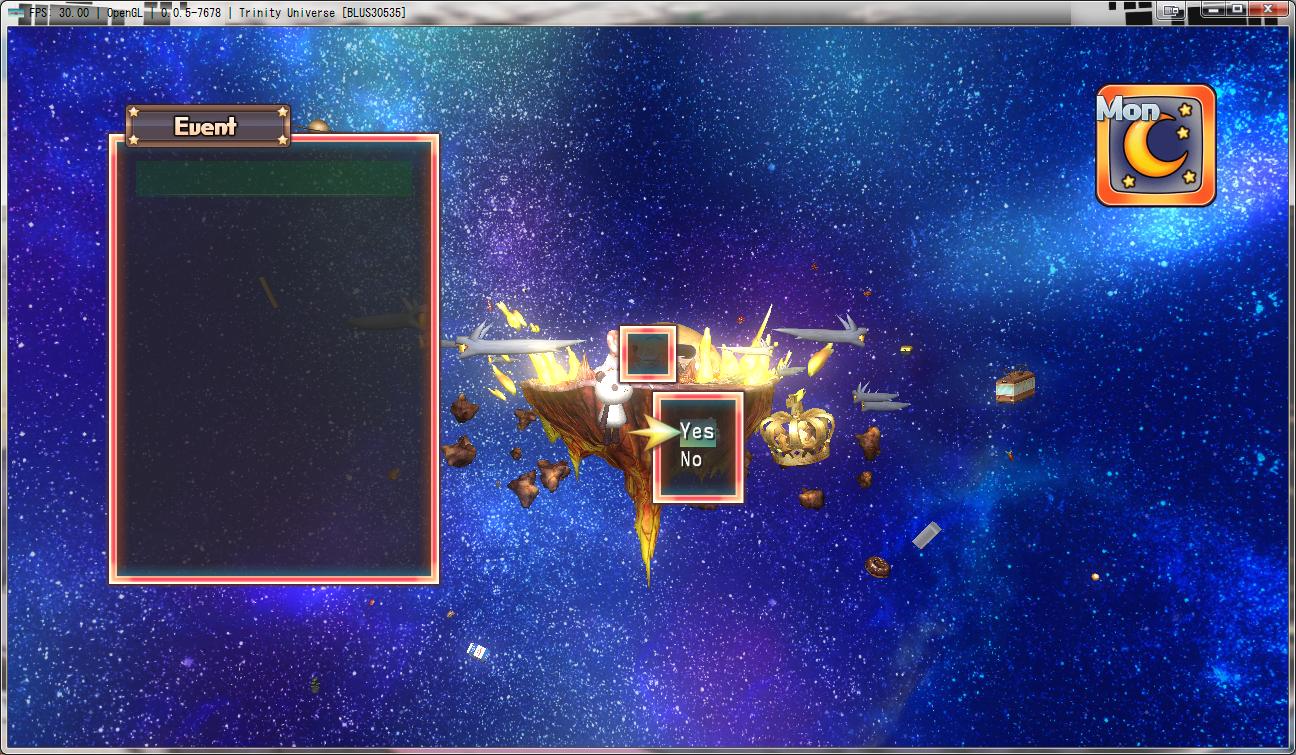 [/spoiler]
[/spoiler]
The font probably does not support accents, but I wrote that way to check. I believe it happened because this file has a limited amount of characters as almost every console game, am I right?
Yesterday I edited a main.dat (which I didn't have to extract from a .cl3) and once I added it to the game, every text inside that file disappeared.
[spoiler]
[/spoiler]The font probably does not support accents, but I wrote that way to check. I believe it happened because this file has a limited amount of characters as almost every console game, am I right?
-
TheUkrainianBard
- Posts: 121
- Joined: Sun May 01, 2016 10:06 pm
Re: [PC] Megadimension Neptunia VII (.pac; .cl3; .arc)
NepTools should work here